Technical Deep Dive
Unveiling the innovations that power DeepSeek R2's exceptional performance and efficiency.
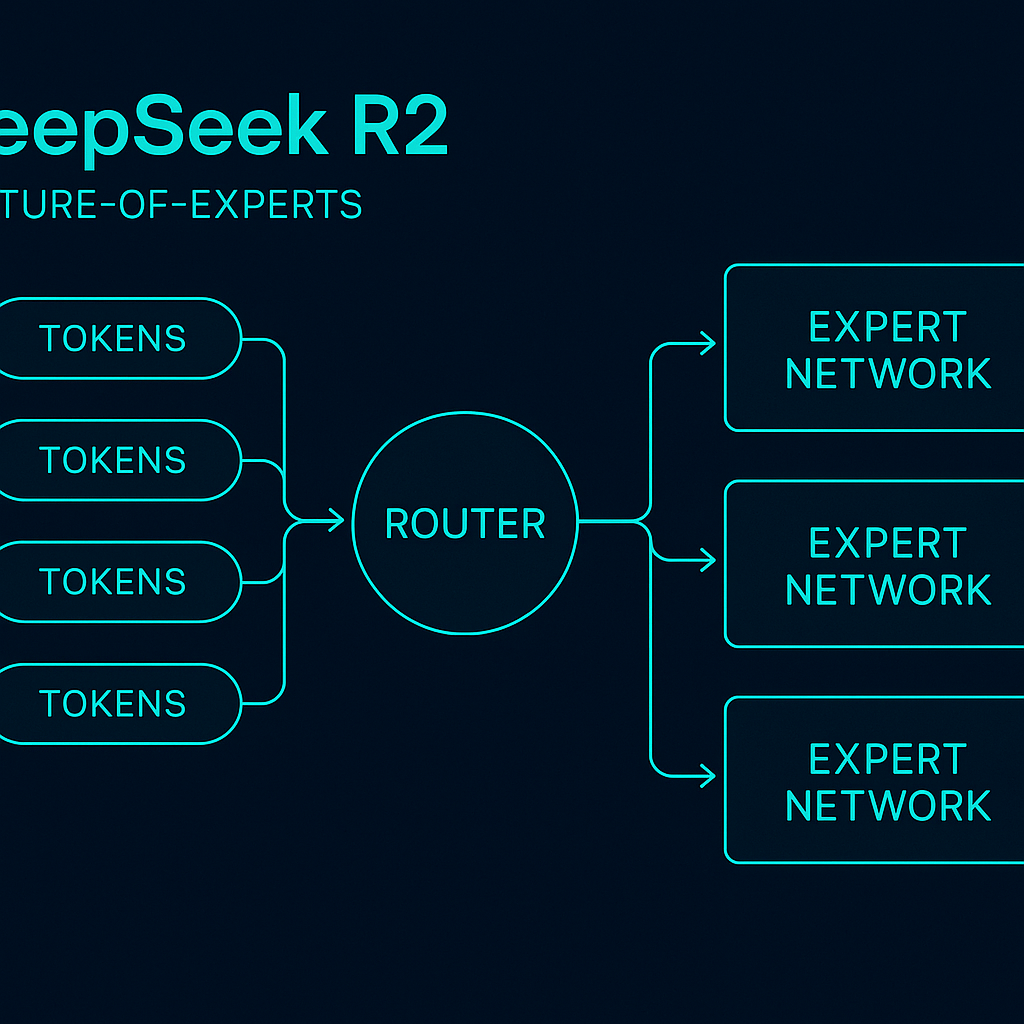
Hybrid MoE Architecture
DeepSeek R2 utilizes a groundbreaking Hybrid Mixture-of-Experts (MoE) architecture. This approach balances an enormous total parameter count with a much smaller number of active parameters for any given input, achieving unparalleled efficiency.
- 1.2 Trillion total parameters, establishing a vast knowledge base.
- 78 Billion active parameters, ensuring rapid and cost-effective inference.
This structure is enhanced by innovations like Multi-head Latent Attention (MLA), which significantly reduces the KV cache, further boosting inference speed and lowering computational costs.

Ultra-long Context Processing
DeepSeek R2 is engineered to handle extremely long contexts, capable of processing up to 128K tokens. This is crucial for applications requiring a deep understanding of extensive documents, complex codebases, or lengthy conversations.
Our architecture efficiently manages attention over these vast sequences, enabling the model to maintain coherence, recall fine-grained details, and perform complex reasoning tasks that were previously intractable, all while maintaining high throughput and cost-efficiency.
Massive, High-Quality Training Data
The model's prowess is built upon a vast and diverse dataset of 5.2 PB, sourced from a high-quality, multi-source corpus. This includes a rich collection of code, mathematical, scientific, and specialized domain data, with a significant proportion of high-quality Chinese content to ensure strong multilingual capabilities.
Pioneering Training Techniques
Generative Reward Modeling (GRM)
Unlike traditional methods, GRM allows the model to generate its own feedback during training. This fosters a more nuanced understanding of human preferences and values, leading to better alignment without relying on massive, manually curated feedback datasets.
Self-Principled Critique Tuning
This innovative technique empowers the model to critically evaluate its own outputs based on a core set of principles. This self-reflection capability significantly reduces hallucinations, improves reasoning, and enhances the coherence and accuracy of its responses over time.
Beyond Text: Multimodal Capabilities
DeepSeek R2 extends beyond text, incorporating powerful capabilities to process and understand images. It achieves a remarkable 92.4% mAP on the COCO dataset, enabling more intuitive and comprehensive human-AI interaction.
Hardware Optimization
Designed for efficient real-world deployment, the model is optimized for specific hardware accelerators. This ensures high utilization rates (e.g., 82%) and peak performance, making advanced AI more practical and scalable.